开源低代码平台开发实践二:从 0 构建一个基于 ER 图的低代码后端
前后端分离了!
第一次知道这个事情的时候,内心是困惑的。
前端都出去搞 SPA,SEO 们同意吗?
后来,SSR 来了。
他说:“SEO 们同意了!”
任何人的反对,都没用了,时代变了。
各种各样的 SPA 们都来了,还有穿着跟 SPA 们一样衣服的各种小程序们。
为他们做点什么吧?于是 rxModels 诞生了,作为一个不希望被抛弃的后端,它希望能以更便捷的方式服务前端。
顺便把如何设计制作也分享出来吧,说不定会有一些借鉴意义。即便有不合理的地方,也会有人友善的指出来。
保持开放,付出与接受会同时发生,是双向受益的一个过程。
rxModels 是什么?#
一个款开源、通用、低代码后端。
使用 rxModels,只需要绘制 ER 图就可以定制一个开箱即用的后端。提供粒度精确到字段的权限管理功能,并对实例级别的权限管理提供表达式支持。
主要模块有:图形化的实体、关系管理界面( rx-models Client),通用JSON格式的数据操作接口服务( rx-models ),前端调用辅助 Hooks 库( rxmodels-swr )等。
rxModels 基于 TypeScript,NestJS,TypeORM 和 Antv x6 实现。
TypeScript 的强类型支持,可以把一些错误在编译时就解决掉了,IDE有了强类型的支持,可以自动引入依赖,提高了开发效率,节省了时间。
TypeScript 编译以后的目标执行码时JS,一种运行时解释语言,这个特性赋予了 rxModels 动态发布实体和热加载 指令 的能力。用户可以使用 指令 实现业务逻辑,扩展通用 JSON 数据接口。给 rxModels 增加了更多使用场景。
NestJS 有助于代码的组织,使其拥有一个良好的架构。
TypeORM 是一款轻量级 ORM 库,可以把对象模型映射到关系数据库。它能够 “分离实体定义”,传入 JSON 描述就可以构建数据库,并对数据库提供面向对象的查询支持。得益于这个特性,图形化的业务模型转换成数据库数据库模型,rxModels 仅需要少量代码就可以完成。
AntV X6 功能相对已经比较全面了,它支持在节点(node)里面嵌入 React组件,利用这个个性,使用它来绘制 ER 图,效果非常不错。如果后面有时间,可以再写一篇文章,介绍如何使用 AntV x6绘制 ER 图。
要想跟着本文,把这个项目一步步做出来,最好能够提前学习一下本节提到的技术栈。
rxModels 目标定位#
主要为中小项目服务。
为什么不敢服务大项目?
真不敢,作者是业余程序员,没有大项目相关的任何经验。
梳理数据及数据映射#
先看一下演示,从直观上知道项目的样子:rxModels演示 。
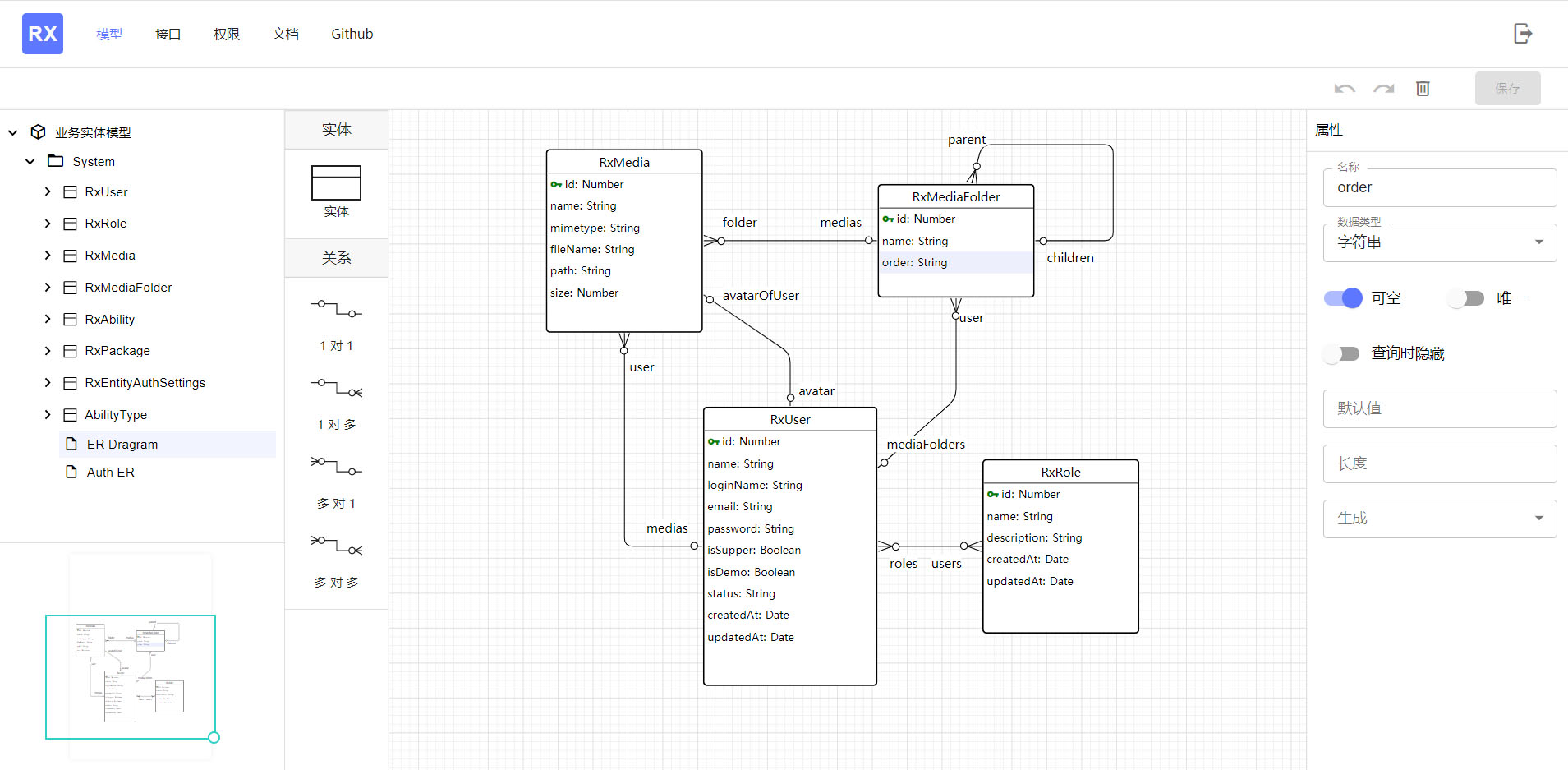
元数据定义#
元数据(Meta),用于描述业务实体模型的数据。一部分元数据转化成 TypeORM 实体定义,随之生成数据库;另一部分元数据业务模型是图形信息,比如实体的大小跟位置,关系的位置跟形状等。
需要转化成 TypeORM 实体定义的元数据有:
import { ColumnMeta } from "./column-meta";
/*** 实体类型枚举,目前仅支持普通实体跟枚举实体,* 枚举实体类似语法糖,不映射到数据库,* 枚举类型的字段映射到数据库是string类型*/export enum EntityType{ NORMAL = "Normal", ENUM = "Enum",}
/*** 实体元数据*/export interface EntityMeta{ /** 唯一标识 */ uuid: string;
/** 实体名称 */ name: string;
/** 表名,如果tableName没有被设置,会把实体名转化成蛇形命名法,并以此当作表名 */ tableName?: string;
/** 实体类型 */ entityType?: EntityType|"";
/** 字段元数据列表 */ columns: ColumnMeta[];
/** 枚举值JSON,枚举类型实体使用,不参与数据库映射 */ enumValues?: any;}
/*** 字段类型,枚举,目前版本仅支持这些类型,后续可以扩展*/export enum ColumnType{
/** 数字类型 */ Number = 'Number',
/** 布尔类型 */ Boolean = 'Boolean',
/** 字符串类型 */ String = 'String',
/** 日期类型 */ Date = 'Date',
/** JSON类型 */ SimpleJson = 'simple-json',
/** 数组类型 */ SimpleArray = 'simple-array',
/** 枚举类型 */ Enum = 'Enum'}
/*** 字段元数据,基本跟 TypeORM Column 对应*/export interface ColumnMeta{
/** 唯一标识 */ uuid: string;
/** 字段名 */ name: string;
/** 字段类型 */ type: ColumnType;
/** 是否主键 */ primary?: boolean;
/** 是否自动生成 */ generated?: boolean;
/** 是否可空 */ nullable?: boolean;
/** 字段默认值 */ default?: any;
/** 是否唯一 */ unique?: boolean;
/** 是否是创建日期 */ createDate?: boolean;
/** 是否是更新日期 */ updateDate?: boolean;
/** 是否是删除日期,软删除功能使用 */ deleteDate?: boolean;
/** * 是否可以在查询时被选择,如果这是为false,则查询时隐藏。 * 密码字段会使用它 */ select?: boolean;
/** 长度 */ length?: string | number;
/** 当实体是枚举类型时使用 */ enumEnityUuid?:string;
/** * ============以下属性跟TypeORM对应,但是尚未启用 */ width?: number; version?: boolean; readonly?: boolean; comment?: string; precision?: number; scale?: number;}/** * 关系类型 */export enum RelationType { ONE_TO_ONE = 'one-to-one', ONE_TO_MANY = 'one-to-many', MANY_TO_ONE = 'many-to-one', MANY_TO_MANY = 'many-to-many',}
/** * 关系元数据 */export interface RelationMeta { /** 唯一标识 */ uuid: string;
/** 关系类型 */ relationType: RelationType;
/** 关系的源实体标识 */ sourceId: string;
/** 关系目标实体标识 */ targetId: string;
/** 源实体上的关系属性 */ roleOnSource: string;
/** 目标实体上的关系属性 */ roleOnTarget: string;
/** 拥有关系的实体ID,对应 TypeORM 的 JoinTable 或 JoinColumn */ ownerId?: string;}不需要转化成 TypeORM 实体定义的元数据有:
/** * 包的元数据 */export interface PackageMeta{ /** ID,主键 */ id?: number;
/** 唯一标识 */ uuid: string;
/** 包名 */ name: string;
/**实体列表 */ entities?: EntityMeta[];
/**ER图列表 */ diagrams?: DiagramMeta[];
/**关系列表 */ relations?: RelationMeta[];}import { X6EdgeMeta } from "./x6-edge-meta";import { X6NodeMeta } from "./x6-node-meta";
/** * ER图元数据 */export interface DiagramMeta { /** 唯一标识 */ uuid: string;
/** ER图名称 */ name: string;
/** 节点 */ nodes: X6NodeMeta[];
/** 关系的连线 */ edges: X6EdgeMeta[];}
export interface X6NodeMeta{ /** 对应实体标识uuid */ id: string; /** 节点x坐标 */ x?: number; /** 节点y坐标 */ y?: number; /** 节点宽度 */ width?: number; /** 节点高度 */ height?: number;}import { Point } from "@antv/x6";
export type RolePosition = { distance: number, offset: number, angle: number,}export interface X6EdgeMeta{ /** 对应关系 uuid */ id: string;
/** 折点数据 */ vertices?: Point.PointLike[];
/** 源关系属性位置标签位置 */ roleOnSourcePosition?: RolePosition;
/** 目标关系属性位置标签位置 */ roleOnTargetPosition?: RolePosition;}rxModels有一个后端服务,基于这些数据构建数据库。
rxModels有一个前端管理界面,管理并生产这些数据。
服务端 rx-models#
整个项目的核心,基于NestJS构建。需要安装TypeORM,只安装普通 TypeORM 核心项目,不需要安装 NestJS 封装版。
nest new rx-models
cd rx-models
npm install npm install typeorm这只是关键安装,其他的库,不一一列举了。
具体项目已经完成,代码地址:https://github.com/rxdrag/rx-models。
第一个版本承担技术探索的任务,仅支持 MySQL 足够了。
通用JSON接口#
设计一套接口,规定好接口语义,就像 GraphQL 那样。这样做的是优势,就是不需要接口文档,也不需要定义接口版本了。
接口以 JSON 为参数,返回也是 JSON 数据,可以叫 JSON 接口。
查询接口#
接口描述:
url: /get/jsonstring...method: get返回值:{ data:any, pagination?:{ pageSize: number, pageIndex: number, totalCount: number }}URL 长度是 2048 个字节,这个长度传递一个查询字符串足够用了,在查询接口中,可以把 JSON 查询参数放在 URL 里,使用 get 方法查数据。
把 JSON 查询参数放在 URL 里,有一个明显的优势,就是客户端可以基于 URL 缓存查询结果,比如使用 SWR 库。
有个特别需要注意的点就是URL转码,要不然查询时,like 使用 % 会导致后端出错。所以,给客户端写一套查询 SDK,封装这些转码类操作是有必要的。
查询接口示例#
传入实体名字,就可以查询实体的实例,比如要查询所有的文章(Post),可以这么写:
{ "entity": "Post"}要查询 id = 1 的文章,则这样写:
{ "entity": "Post", "id": 1}把文章按照标题和日期排序,这么写:
{ "entity": "Post", "@orderBy": { "title": "ASC", "updatedAt": "DESC" }}只需要查询文章的 title 字段,这么写:
{ "entity": "Post", "@select": ["title"]}这么写也可以:
{ "entity @select(title)": "Post"}只取一条记录:
{ "entity": "Post", "@getOne": true}或者:
{ "entity @getOne": "Post"}只查标题中有“水”字的文章:
{ "entity": "Post", "title @like": "%水%"}还需要更复杂的查询,内嵌类似 SQL 的表达式吧:
{ "entity": "Post", "@where": "name %like '%风%' and ..."}数据太多了,分页,每页25条记录取第一页:
{ "entity": "Post", "@paginate": [25, 0]}或者:
{ "entity @paginate(25, 0)": "Post"}关系查询,附带文章的图片关系 medias :
{ "entity": "Post", "medias": {}}关系嵌套:
{ "entity": "Post", "medias": { "owner":{} }}给关系加个条件:
{ "entity": "Post", "medias": { "name @like": "%风景%" }}只取关系的前5个
{ "entity": "Post", "medias @count(5)": {}}聪明的您,可以按照这个方向,对接口做进一步的设计更改。
@ 符号后面的,称之为 指令。
把业务逻辑放在指令里,可以对接口进行非常灵活的扩展。比如在文章内容(content)底部附加加一个版权声明,可以定义一个 @addCopyRight 指令:
{ "entity": "Post", "@addCopyRight": "content"}或者:
{ "entity @addCopyRight(content)": "Post"}指令看起来是不是像一个插件?
既然是个插件,那就赋予它热加载的能力!
通过管理界面,上传第三方指令代码,就可以把指令插入系统。
第一版不支持指令上传功能,但是架构设计已经预留了这个能力,只是配套的界面没做。
post 接口#
接口描述:
url: /postmethod: post参数: JSON返回值: 操作成功的对象通过post方法,传入JSON数据。
预期post接口具备这样的能力,传入一组对象组合(或者说附带关系约束的对象树),直接把这组对象同步到数据库。
如果给对象提供了id字段,则更新已有对象,没有提供id字段,则创建新对象。
post接口示例#
上传一篇文章,带图片关联,可以这么写:
{ "Post": { "title": "轻轻的,我走了", "content": "...", // 作者关联 id "author": 1, // 图片关联 id "medias":[3, 5, 6 ...] }}也可以一次传入多篇文章
{ "Post": [ { "id": 1, "title": "轻轻的,我走了", "content": "内容有所改变...", "author": 1, "medias":[3, 5, 6 ...] }, { "title": "正如,我轻轻的来", "content": "...", "author": 1, "medias": [6, 7, 8 ...] } ]}第一篇文章有id字段,是更新数据库的操作,第二篇文章没有id字段,是创建新的。
也可以传入多个实体的实例,类似这样,同时传入文章(Post)跟媒体(Media)的实例:
{ "Post": [ { ... }, { ... } ], "Media": [ { ... } ]}可以把关联一并传入,如果一篇文章关联一个 SeoMeta 对象,创建文章时,一并创建 SeoMeta:
{ "Post": { "title": "轻轻的,我走了", "content": "...", "author": 1, "medias":[3, 5, 6 ...], "seoMeta":{ "title": "诗篇解读:轻轻的,我走了|诗篇解读网", "descript": "...", "keywords": "诗篇,解读,诗篇解读" } }}传入这个参数,会同时创建两个对象,并在它们之间建立关联。
正常情况下删除这个关联,可以这样写:
{ "Post": { "title": "轻轻的,我走了", "content": "...", "author": 1, "medias":[3, 5, 6 ...], "seoMeta":null }}这样的方式保存文章,会删除跟 SeoMeta 的关联,但是 SeoMeta 的对象并没有被删除。别的文章也不需要这个 SeoMeta,不主动删除它,数据库里就会生成一条垃圾数据。
保存文章的时候,添加一个 @cascade 指令,能解决这个问题:
{ "Post @cascade(medias)": { "title": "轻轻的,我走了", "content": "...", "author": 1, "medias":[3, 5, 6 ...], "seoMeta":null }}@cascade 指令会级联删除与之关联的 SeoMeta 对象。
这个指令能放在关联属性上,写成这样吗?
{ "Post": { "title": "轻轻的,我走了", "content": "...", "author": 1, "medias @cascade":[3, 5, 6 ...], "seoMeta":null }}最好不要这样写,客户端用起来不会很方便。
自定义指令可以扩展post接口,比如,要加一个发送邮件的业务,可以开发一个 @sendEmail 指令:
{ "Post @sendEmail(title, content, water@rxdrag.com)": { "title": "轻轻的,我走了", "content": "...", "author": 1, "medias @cascade":[3, 5, 6 ...], }}假设每次保存文章成功后,sendEmail 指令都会把标题跟内容,发送到指定邮箱。
update 接口#
接口描述:
url: /updatemethod: post参数: JSON返回值: 操作成功的对象post 接口已经具备了 update 功能了,为什么还要再做一个 update 接口?
有时候,需要一个批量修改一个或者几个字段的能力,比如把指定的消息标记为已读。
为了应对这样的场景,设计了 update 接口。假如,要所有文章的状态更新为“已发布”:
{ "Post": { "status": "published", "@ids":[3, 5, 6 ...], }}基于安全方面的考虑,接口不提供条件指令,只提供 @ids 指令(遗留原因,演示版不需要@符号,直接写 ids 就行,后面会修改)。
delete 接口#
接口描述:
url: /deletemethod: post参数: JSON返回值: 被删除的对象delete 接口跟 update 接口一样,不提供条件指令,只接受 id 或者 id 数组。
要删除文章,只需要这么写:
{ "Post": [3, 5, ...]}这样的删除,跟 update 一样,也不会删除跟文章相关的对象,级联删除的话需要指令 @cascade。
级联删除 SeoMeta,这么写:
{ "Post @cascade(seoMeta)": [3, 5, ...]}upload 接口#
url: /uploadmethod: post参数: FormDataheaders: {"Content-Type": "multipart/form-data;boundary=..."}返回值: 上传成功后生成RxMedia对象rxModels 最好提供在线文件管理服务功能,跟第三方的对象管理服务,比如腾讯云、阿里云、七牛什么的,结合起来。
第一版先不实现跟第三方对象管理的整合,文件存在本地,文件类型仅支持图片。
用实体 RxMedia 管理这些上传的文件,客户端创建FormData,设置如下参数:
{ "entity": "RxMedia", "file": ..., "name": "文件名" }全部JSON接口介绍完了,接下就是如何实现并使用这些接口。
继续之前,说一下为什么选用JSON,而不用其他方式。
为什么不用 oData#
开始这个项目的时候,对 oData 并不了解。
简单查了点资料,说是,只有在需要Open Data(开放数据给其他组织)时候,才有必要按照OData协议设计RESTful API。
如果不是把数据开放给其他组织,引入 oData 增加了发杂度。需要开发解析oData参数解析引擎。
oData 出了很长时间,并没有多么流行,还不如后来的 GraphQL 知名度高。
为什么不用 GraphQL?#
尝试过,没用起来。
一个人,做开源项目,只能接入现有的开源生态。一个人什么都做,是不可能完成的任务。
要用GraphQL,只能用现有的开源库。现有的主流 GraphQL 开源库,大部分都是基于代码生成的。前一篇文章说过,不想做一个基于代码生成的低代码项目。
还有一个原因,目标定位是中小项目。GraphQL对这些中小项目来说,有两个问题:1、有些笨重;2、用户的学习成本高。
有的小项目就三五个页面,拉一个轻便的小后端,很短时间就搭起来了,没有必要用 GraphQL。
GraphQL的学习成本并不低,有些中小项目的用户是不愿意付出这些学习成本的。
综合这些因素,第一个版本的接口,没有使用 GraphQL。
使用 GraphQL 的话,需要怎么做?#
跟一些朋友交流的时候,有些朋友对 GraphQL 还是情有独钟的。并且经过几年的发展,GraphQL 的热度慢慢开始上来了。
假如使用 GraphQL 做一个类似项目,需要怎么做呢?
需要自己开发一套 GraphQL 服务端,这个服务端类似 Hasura,不能用代码生成机制,使用动态运行机制。Hasura 把 GQL 编译成 SQL,你可以选择这样做,也可以不选择这样做,只要能不经过编译过程,就把对象按照 GQL 查询要求,拉出来就行。
需要在 GraphQL 的框架下,充分考虑权限管理,业务逻辑扩展和热加载等方面。这就需要对 GraphQL 有比较深入的理解。
如果要做低代码前端,那么还需要做一个特殊的前端框架,像 apollo 这样的 GraphQL 前端库库,并不适合做低代码前端。因为低代码前端需要动态类型绑定,这个需求跟这些前端库的契合,并不是特别理想。
每一项,都需要大量时间跟精力,不是一个人能完成的工作,需要一个团队。
或有一天,有机会,作者也想进行这样方面的尝试。
但也未必会成功,GraphQL 本身并不代表什么,假如它能够使用者带来实实在在的好处,才是被选择的理由。
登录验证接口#
使用 jwt 验证机制,实现两个登录相关的接口。
url: /auth/loginmethod: post参数: { username: string, password: string}返回值:jwt tokenurl: /auth/memethod: get返回值: 当前登录用户,RxUser类型这两个接口实现起来,没有什么难的,跟着NestJs文档做一下就行了。
元数据存储#
客户端通过 ER 图的形式生产的元数据,存储在数据库,一个实体 RxPackage就够了:
export interface RxPackage { /* id 数据库主键 */ id: number;
/** 唯一标识uuid,当不同的项目之间共享元数据时,这个字段很有用 */ uuid: string;
/** 包名 */ name: string;
/** 包的所有实体元数据,以JSON形式存于数据库 */ entities: any;
/** 包的所有 ER 图,以JSON形式存于数据库 */ diagrams?: any;
/** 包的所有关系,以JSON形式存于数据库 */ relations?: any;}数据映射完成后,在界面中看到的一个包的所有内容,就对应 rx_package 表的一条数据记录。
这些数据怎么被使用呢?
我们给包增加一个发布功能,如果包被发布,就根据这条数据库记录,做一个JSON文件,放在 schemas 目录下,文件名就是 ${uuid}.json。
服务端创建 TypeORM 连接时,热加载这些JSON文件,并把它们解析成 TypeORM 实体定义数据。
应用安装接口#
rxModels 的最终目标是,发布一个代码包,使用者通过图形化界面安装即可,不要接触代码。

两页向导,即可完成安装,需要接口:
url: installmethod: post参数: { /** 数据库类型 */ type: string;
/** 数据库所在主机 */ host: string;
/** 数据库端口 */ port: string;
/** 数据库schema名 */ database: string;
/** 数据登录用户 */ username: string;
/** 数据库登录密码 */ password: string;
/** 超级管理员登录名 */ admin: string;
/** 超级管理员密码 */ adminPassword: string;
/** 是否创建演示账号 */ withDemo: boolean;}还需要一个查询是否已经安装的接口:
url: /is-installedmethod: get返回值: { installed: boolean}只要完成这些接口,后端的功能就实现了,加油!
架构设计#
得益于 NestJs 优雅的框架,可以把整个后端服务分为以下几个模块:
auth, 普通 NestJS module,实现登录验证接口。本模块很简单,后面不会单独介绍了。
package-manage, 元数据的管理发布模块。
install, 普通 NestJS module,实现安装功能。
schema, 普通 NestJS module,管理系统元数据,并把前面定义的格式的元数据,转化成 TypeORM 能接受的实体定义,核心代码是
SchemaService。typeorm, 对 TypeORM 的封装,提供带有元数据定义的 Connection,核心代码是
TypeOrmService,该模块没有 Controller。magic, 项目最核心模块,通用JSON接口实现模块。
directive, 指令定义模块,定义指令功能用到的基础类,热加载指令,并提供指令检索服务。
directives, 所有指令实现类,系统从这个目录热加载所有指令。
magic-meta, 解析JSON参数用到的数据格式,主要使用模块是
magic,由于directive模块也会用到这些数据,为了避免模块之间的循环依赖,把这部分数据抽出来,单独作为一个模块,那两个模块同时依赖这个模块。entity-interface, 系统种子数据类型接口,主要用于 TypeScript 编译器的类型识别。客户端的代码导出功能导出的文件,直接复制过来的。客户端也会复制一份同样的代码来用。
包管理 package-manage#
提供一个接口 publishPackages。把参数传入的元数据,发布到系统里,同步到数据库模式:
就是一个包一个文件,放在根目录的
schemas目录下,文件名就是包的uuid+ .json 后缀。通知 TypeORM 模块重新创建数据库连接,同时同步数据库。
安装模块 install#
模块内有一个种子文件 install.seed.json,里面是系统预置的一些实体,格式就是上文定义的元数据格式,这些数据统一组织在 System 包里。
客户端没有完成的时候,手写了一个 ts 文件用于调试,客户端完成以后,直接利用包的导出功能,导出了一个 JSON 文件,替换了手写的 ts 文件。相当于基础数据部分,可以自举了。
这个模块的核心代码在 InstallService 里,它分步完成:
把客户端传来的数据库配置信息,写入根目录的dbconfig.json 文件。
把
install.seed.json文件里面的预定义包发布。直接调用上文说的publishPackages实现发布功能。
元数据管理模块 schema#
该模块提供一个 Controller,名叫 SchemaController。提供一个 get 接口 /published-schema,用于获取已经发布的元数据信息。
这些已经发布的元数据信息可以被客户端的权限设置模块使用,因为只有已经发布的模块,对它设置权限才有意义。低代码可视化编辑前端,也可以利用这些信息,进行下拉选择式的数据绑定。
核心类 SchemaService,还提供了更多的功能:
从
/schemas目录下,加载已经发布的元数据。把这些元数据组织成列表+树的结构,提供按名字、按UUID等方式的查询服务。
把元数据解析成 TypeORM 能接受的实体定义 JSON。
封装 TypeORM#
自己写一个 ORM 库工作量是很大的,不得不使用现成的,TypeORM 是个不错的选择,一来,她像个年轻的姑娘,漂亮又活力四射。二来,她不像 Prisma 那么臃肿。
为了迎合现有的 TyeORM,有些地方不得不做妥协。这种低代码项目后端,比较理想的实现方式自己做一个 ORM 库,完全根据自己的需求实现功能,那样或许就有青梅竹马的感觉了,但是需要团队,不是一个人能完成。
既然是一个人,那么就安心做一个人能做的事情好了。
TypeORM 只有一个入口能够传入实体定义,就是 createConnection。需要在这个函数调用前,解析完元数据,分离出实体定义。这个模块的 TypeOrmService 完成这些 connection 的管理工作,依赖的 schema 模块的 SchemaService。
通过 TypeOrmService 可以重启当前连接(关闭并重新创建),以更新数据库定义。创建连接的时候,使用 install 模块创建的 dbconfig.json 文件获取数据库配置。注意,TypeORM 的 ormconfig.json 文件是没有被使用的。
magic 模块#
在 magic 模块,不管查询还是更新,每一个接口实现的操作,都在一个完整的事务里。
难道查询接口也要包含在一个事务里?
是的,因为有的时候查询可能会包含一些简单操作数据库的指令,比如查询一篇文章的时候,顺便把它的阅读次数 +1。
magic 模块的增删查改等操作,都受到权限的约束,把它的核心模块 MagicInstanceService 传递给指令,指令代码里可以放心使用它的接口操作数据库,不需要关心权限问题。
MagicInstanceService#
MagicInstanceService 是接口 MagicService 的实现。接口定义:
import { QueryResult } from 'src/magic-meta/query/query-result';import { RxUser } from 'src/entity-interface/RxUser';
export interface MagicService { me: RxUser;
query(json: any): Promise<QueryResult>;
post(json: any): Promise<any>;
delete(json: any): Promise<any>;
update(json: any): Promise<any>;}
magic 模块的 Controller 直接调用这个类,实现上文定义的接口。
AbilityService#
权限管理类,查询当前登录用户的实体跟字段的权限配置。
query#
/magic/query 目录,实现 /get/json... 接口的代码。
MagicQuery 是核心代码,实现查询业务逻辑。它使用 MagicQueryParser 把传入的 JSON 参数,解析成一棵数据树,并分离相关指令。数据结构定义在 /magic-meta/query 目录。代码量太大,没有精力一一解析。自己翻阅一下,有问题可以跟作者联系。
需要特别注意的是 parseWhereSql 函数。这个函数负责解析类似 SQL Where 格式的语句,使用了开源库 sql-where-parser。
把它放在这个目录,是因为 magic 模块需要用到它,同时 directive 模块也需要用到它,为了避免模块的循环依赖,把它独立抽到这个目录。
/magic/query/traverser 目录存放一些遍历器,用于处理解析后的树形数据。
MagicQuery 使用 TypeORM 的 QueryBuilder 构建查询。关键点:
使用 directive 模块的
QueryDirectiveService获取指令处理类。指令处理类可以:1、构建QueryBuilder用到的条件语句,2、过滤查询结果。从
AbilityService拿到权限配置,根据权限配置修改QueryBuilder, 根据权限配置过滤查询结果中的字段。QueryBuilder 用到的查询语句分两部分:1、影响查询结果数量的语句,比如 take 指令、paginate指令。这些指令只是要截取指令数量的结果;2、其他没有这种影响的查询语句。因为分页时,需要返回一个总的记录条数,用第二类查询语句先查一次数据库,获得总条数,然后加入第一类查询语句获得查询结果。
post#
/magic/post 目录,实现 /post 接口的代码。
MagicPost 类是核心代码,实现业务逻辑。它使用 MagicPostParser 把传入的JSON参数,解析成一棵数据树,并分离相关指令。数据结构定义在 /magic-meta/post 目录。它可以:
递归保存关联对象,理论上可以无限嵌套。
根据
AbilityService做权限检查。使用 directive 模块的
PostDirectiveService获取指令处理类, 在实例保存前跟保存后会调用指令处理程序,详情请翻阅代码。
update#
/magic/update 目录,实现 /update 接口的代码。
功能简单,代码也简单。
delete#
/magic/delete 目录,实现 /delete 接口的代码。
功能简单,代码也简单。
upload#
/magic/upload 目录,实现 /upload 接口的代码。
upload 目前功能比较简单,后面可以考添加一些裁剪指令等功能。
directive 模块#
指令服务模块。热加载指令,并对这些指令提供查询服务。
这个模块也比较简单,热加载使用的是 require 语句。
关于后端,其它模块就没什么好说的,都很简单,直接看一下代码就好。
客户端 rx-models-client#
需要一个客户端,管理生产并管理元数据,测试通用数据查询接口,设置实体权限,安装等。创建一个普通的 React 项目, 支持 TypeScript。
npx create-react-app rx-models-client--template typescript这个项目已经完成了,在GitHub上,代码地址:https://github.com/rxdrag/rx-models-client。
代码量有点多,全部在这里展开解释,有点放不下。只能挑关键点说一下,有问题需要交流的话,请跟作者联系。
ER图 - 图形化的业务模型#
这个模块是客户端的核心,看起来比较唬人,其实一点都不难。目录 src/components/entity-board下,是该模块全部代码。
得益于 Antv X6,使得这个模块的制作比预想简单了许多。
X6 充当的角色,只是一个视图层。它只负责渲染实体图形跟关系连线,并传回一些用户交互事件。它用于撤销、重做的操作历史功能,在这个项目里用不上,只能全部自己写。
Mobx 在这个模块也占非常重要的地位,它管理了所有的状态并承担了部分业务逻辑。低代码跟拖拽类项目,Mobx 确实非常好用,值得推荐。
定义 Mobx Observable 数据#
上文定义的元数据,每一个对应一个 Mobx Observable 类,再加一个根索引类,这数据相互包含,构成一个树形结构,在 src/components/entity-board/store 目录下。
EntityBoardStore, 处于树形结构的根节点,也是该模块的整体状态数据,它记录下面这些信息:
export class EntityBoardStore{ /** * 是否有修改,用于未保存提示 */ changed = false;
/** * 所有的包 */ packages: PackageStore[];
/** * 当前正在打开的 ER 图 */ openedDiagram?: DiagramStore;
/** * 当前使用的 X6 Graph对象 */ graph?: Graph;
/** * 工具条上的关系被按下,记录具体类型 */ pressedLineType?: RelationType;
/** * 处在鼠标拖动划线的状态 */ drawingLine: LineAction | undefined;
/** * 被选中的节点 */ selectedElement: SelectedNode;
/** * Command 模式,撤销列表 */ undoList: Array<Command> = [];
/** * Command 模式,重做列表 */ redoList: Array<Command> = [];
/** * 构造函数传入包元数据,会自动解析成一棵 Mobx Observable 树 */ constructor(packageMetas:PackageMeta[]) { this.packages = packageMetas.map( packageMeta=> new PackageStore(packageMeta,this) ); makeAutoObservable(this); } /** * 后面大量的set方法,就不需要了展开了 */ ...
}PackageStore, 树形完全跟上文定义的 PackageMeta 一致,区别就是 meta 相关的全都换成了 store 相关的:
export class PackageStore{ id?: number; uuid: string; name: string; entities: EntityStore[] = []; diagrams: DiagramStore[] = []; relations: RelationStore[] = []; status: PackageStatus; constructor(meta:PackageMeta, public rootStore: EntityBoardStore){ this.id = meta.id; this.uuid = meta?.uuid; this.name = meta?.name; this.entities = meta?.entities?.map( meta=>new EntityStore(meta, this.rootStore, this) )||[]; this.diagrams = meta?.diagrams?.map( meta=>new DiagramStore(meta, this.rootStore, this) )||[]; this.relations = meta?.relations?.map( meta=>new RelationStore(meta, this) )||[]; this.status = meta.status; makeAutoObservable(this) }
/** * 省略set方法 */ ...
/** * 最后提供一个把 Store 逆向转成元数据的方法,用于往后端发送数据 */ toMeta(): PackageMeta { return { id: this.id, uuid: this.uuid, name: this.name, entities: this.entities.map(entity=>entity.toMeta()), diagrams: this.diagrams.map(diagram=>diagram.toMeta()), relations: this.relations.map(relation=>relation.toMeta()), status: this.status, } }}依此类推,可以做出 EntityStore、ColumnStore、RelationStore 和 DiagramStore。
前面定义的 X6NodeMeta 和 X6EdgeMeta 不需要制作相应的 store 类,因为没法通过 Mobx 的机制更新 X6 的视图,要用其它方式完成这个工作。
DiagramStore 主要为展示 ER 图提供数据。给它添加两个方法:
export type NodeConfig = X6NodeMeta & {data: EntityNodeData};export type EdgeConfig = X6EdgeMeta & RelationMeta;
export class DiagramStore { ...
/** * 获取当前 ER 图所有的节点,利用 mobx 更新机制, * 只要数据有更改,调用该方法的视图会自动被更新, * 参数只是用了指示当前选中的节点,或者是否需要连线, * 这些状态会影响视图,可以在这里直接传递给每个节点 */ getNodes( selectedId:string|undefined, isPressedRelation:boolean|undefined ): NodeConfig[]
/** * 获取当前 ER 图所有的连线,利用 mobx 更新机制, * 只要数据有更改,调用该方法的视图会自动被更新 */ getAndMakeEdges(): EdgeConfig[]
}
如何使用 Mobx Observable 数据#
使用 React 的 Context,把上面定义的 store 数据传递给子组件。
定义 Context:
export const EnityContext = createContext<EntityBoardStore>({} as EntityBoardStore);export const EntityStoreProvider = EnityContext.Provider;export const useEntityBoardStore = (): EntityBoardStore => useContext(EnityContext);创建 Context:
...const [modelStore, setModelStore] = useState(new EntityBoardStore([]));
... return ( <EntityStoreProvider value = {modelStore}> ... </EntityStoreProvider> )使用的时候,直接在子组件里调用 const rootStore = useEntityBoardStore() 就可以拿到数据了。
树形编辑器#
利用 Mui的树形控件 + Mobx 对象,代码并不复杂,感兴趣的话,翻翻看看,有疑问留言或者联系作者。
如何使用 AntV X6#
X6 支持在节点里嵌入 React 组件,定义一个组件 EntityView 嵌入进去就好。X6 相关代码都在这个目录下:
src/componets/entity-board/grahp-canvas业务逻辑被拆分成很多 React Hooks:
useEdgeChange, 处理关系线被拖动useEdgeLineDraw, 处理画线动过useEdgeSelect, 处理关系线被选中useEdgesShow, 渲染关系线,包括更新useGraphCreate, 创建 X6 的 Grpah对象useNodeAdd, 处理拖入一个节点的动作useNodeChange, 处理实体节点被拖动或者改变大小useNodeSelect, 处理节点被选中useNodesShow, 渲染实体节点,包括更新
撤销、重做#
撤销、重做不仅跟 ER 图相关,还跟整个 store 树相关。这就是说,X6 的撤销、重做机制用不了,只能自己重新做。
好在设计模式中的 Command 模式还算简单,定义一些 Command,并定义好正负操作,可以很容易完成。实现代码在:
src/componets/entity-board/command全局状态 AppStore#
按照上问的方法,利用 Mobx 做一个全局的状态管理类 AppStore,用于管理整个应用的状态,比如弹出操作成功提示,弹出错误信息等。
代码在 src/store 目录下。
接口测试#
代码在 src/components/api-board 目录下。
很简单一个模块,代码应该很容易懂。使用了 rxmodels-swr 库,直接参考它的文档就好。
JSON 输入控件,使用了 monaco 的 react 封装:react-monaco-editor,使用起来很简单,安装稍微麻烦一点,需要安装 react-app-rewired。
monaco 用的还不熟练,后面熟练了可以加入如下功能输入提示和代码校验等功能。
权限管理#
代码在 src/components/auth-board 目录下。
这个模块之主要是后端数据的组织跟接口定义,前端代码很少,基于rxmodels-swr 库完成。
权限定义支持表达式,表达式类似 SQL 语句,并内置了变量 $me 指代当前登录用户。
前端输入时,需要对 SQL 表达式进行校验,所以也引入了开源库 sql-where-parser。
安装、登录#
安装代码在 src/components/install 目录下。
登录页面是 src/components/login.tsx。
代码一眼就能瞅明白。
后记#
这篇文章挺长的,但是还不确定有没有把需要说的说清楚,有问题的话留言或者联系作者吧。
演示能跑起来以后,就已经冒着被踢的危险,在几个 QQ 群发了一下。收到了很多反馈,非常感谢热心的朋友们。
rxModels,终于走出去了第一步...
与前端的第一次接触#
rxModels来了,热情的走向前端们。
前端们皱起了眉头,说:“离远点儿,你不是我们理想中的样子。”
rxModels 说:“我还会改变,还会成长,未来的某一天,我们一定是最好的搭档。”
下一篇文章#
《从 0 构建一个可视化低代码前端》,估计要等一段时间了,要先把前端重构完。